变量的本质和垃圾回收
本文最后更新于:2024年11月17日 晚上
1 | |
从本质上理解变量
程序的本质是一个状态机(数据的集合),程序本质是只能访问栈,不能直接访问堆,但是可以通过标识符间接的访问堆,因为栈的访问速度快(因为栈的大小是确定的,可以直接找到变量的地址)
1.Primitive Type(原始类型)
值不可以改变的类型,是一个二进制的字符串,基本数据类型一般存在栈(FILO)里,还有引用类型的标识符
- NULL
- Undefined
- Boolean
- Number
- BigInt
- String
- Symbol
Stack
1.结构性强,内存连续
2.寻址速度快
3.数据稳定,每一个类型的大小都是确定的
4.容量小
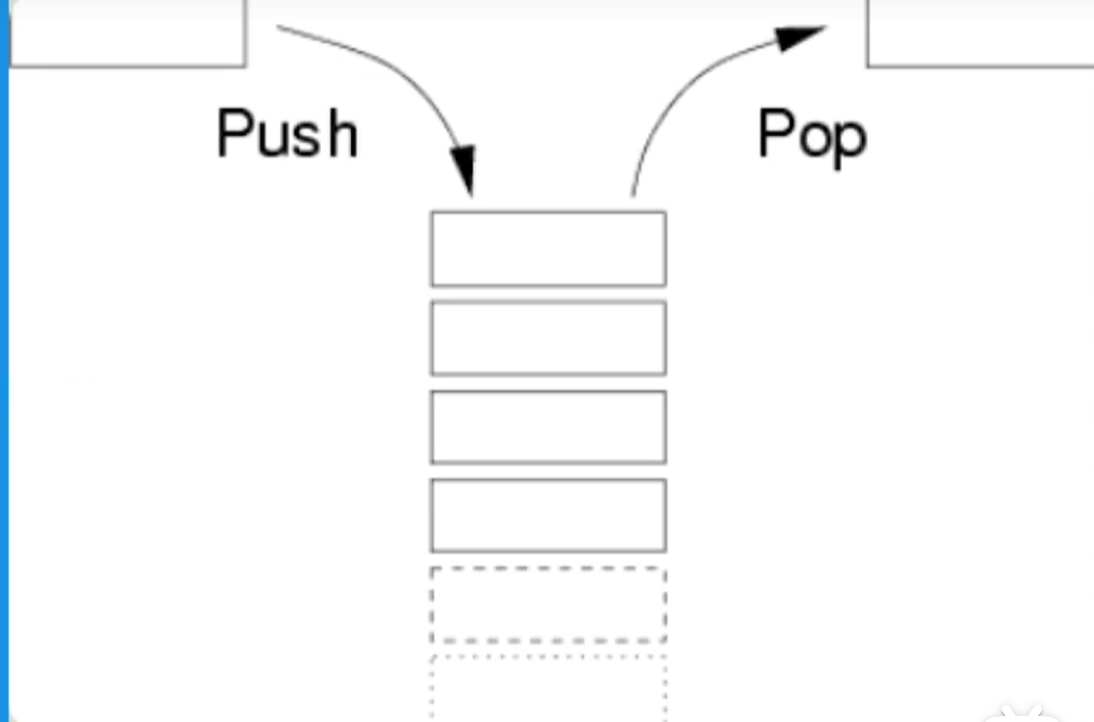
2.Reference Type(引用类型)
Heap
- 树的结构,有大根堆和小根堆
- 存储的大小不一
- 容量大
- 不同数据间内存不连续

Object
Object 是 JavaScript 的一种 数据类型 。它用于存储各种键值集合和更复杂的实体。Objects 可以通过 Object() 构造函数或者使用 对象字面量 的方式创建。
对象是存在堆heap里的,因为对象的大小是不确定而且是可变的,所以不能放在栈里
特殊的字符串
字符串是无法修改的,是基本数据类型,但是其大小又是不确定的。修改值只会重新开辟一块内存空间
浏览器的垃圾回收机制有:标记清除和引用计数
当一个内存单元没有被使用的时候,会被标记为空,下次的数据就可以直接覆盖到上面
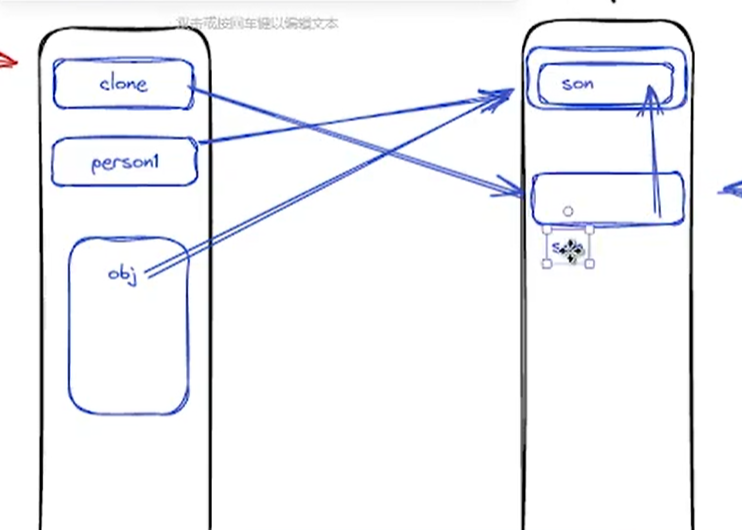
深拷贝和浅拷贝
1 | |
1 | |
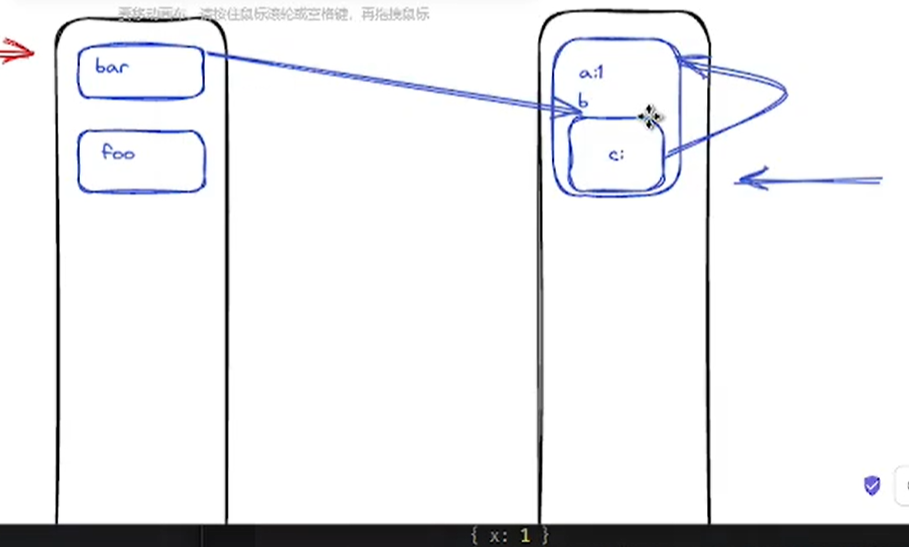
垃圾回收机制
1 | |
原型链
理解new关键字的作用机制
理解 [[GET]]
浏览器
早期的浏览器是一个单进程的,有很多的线程,最重要的就是Page Thread
现代浏览器架构 (多进程)
主进程:
- 浏览器界面
- 用户交互
- 管理子进程
- 提供存储功能
网络进程:负责网络资源的请求和接收
GPU进程
插件进程
渲染进程(内核)
渲染进程是运行在沙箱中的,保证用户的安全,主要是渲染引擎和JS解析引擎
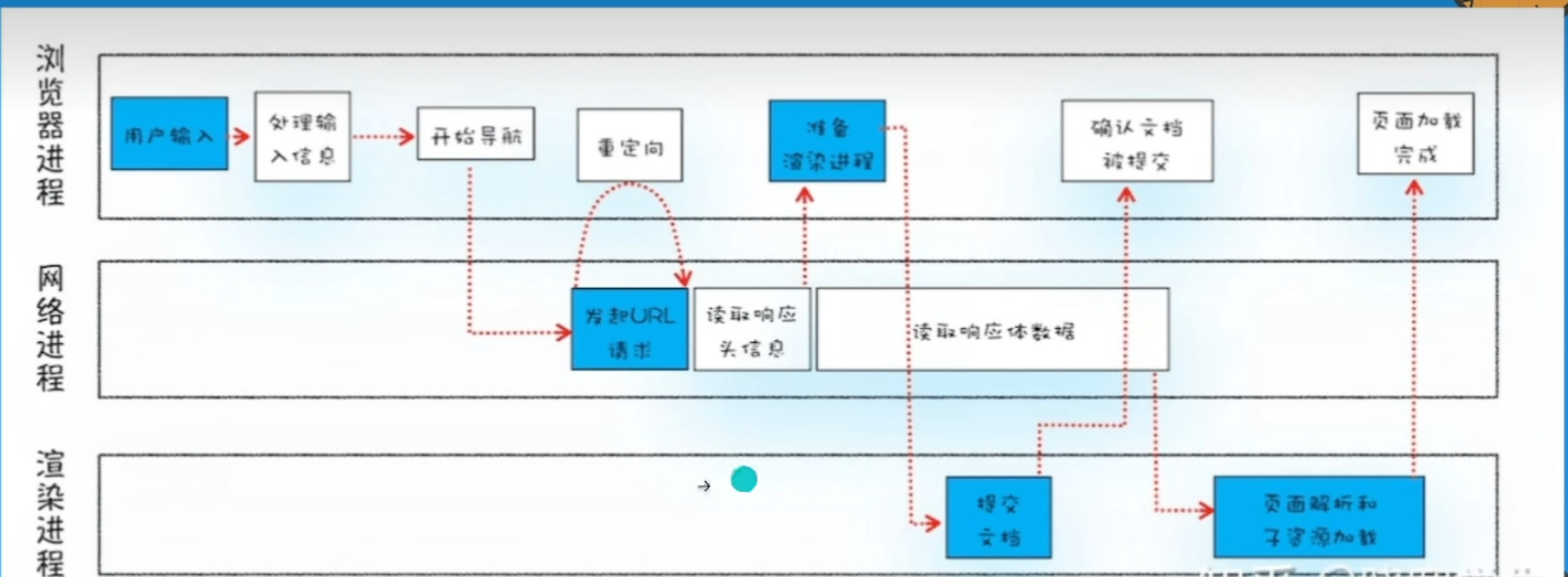
浏览器内核执行机制
浏览器内核也就是渲染进程分别由渲染引擎和JS解析引擎构成
渲染引擎用来渲染页面,JS解析引擎用来解析JS代码,但是两个进程是不能直接通信的,就需要一个中间人来搭建桥梁,也就是事件循环
渲染引擎
- 解析HTML,生成用于构建页面的信息
- 如果遇到Script 标签,则停止解析,就会挂起解析HTML
JS执行机制
- 单线程执行
JS单线程不可怕,可怕的是他与渲染引擎是互斥的,会造成页面卡顿,无响应等
那么如何解决呢? 异步编程就是一种办法
同步: 在主线程中执行的代码
异步: 不在主线程执行,而是通过任务队列通知主线程
- 定时器
- 网络请求
- 与用户的交互
- 。。。。。
任务队列
- 延时队列: 用户存放计时器线程包装的回调任务 优先级: 中
- 交互队列: 用于存放用户操作事件产生后的事件处理任务 优先级: 高
- 微任务队列: 优先级: 最高
只有同步任务执行完了,才会执行异步任务,那么怎么判断同步任务执行完成了呢?
也就是看栈,如果执行栈空了,就说明同步任务执行完了,可以去执行任务队列中的任务了

任务队列

1 | |
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!